
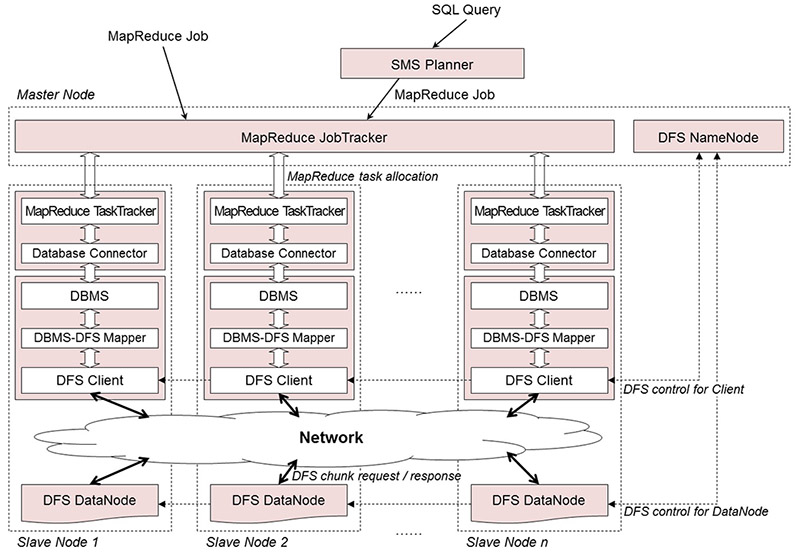
PreliminariesHadoopDB is the first work that uses the MapReduce framework together with the RDBMS for big data analytics. HadoopDB stores data in the distributed file system(DFS) and, at query processing time, loads the data in the DFS to a local database in each node, and then, processes queries by local DBMSs. Hence, HadoopDB has the advantages of both MapReduce and the DBMS. However, HadoopDB has the following drawbacks because the DBMSs that process queries are separated from the DFS that stores the data. First, there is a storage overhead due to redundant storage of data in both the DFS and local databases. Second, HadoopDB causes performance degradation by re-loading the DFS data to local databases when processing queries that cannot be processed using the current snapshot of the local databases. Third, HadoopDB, being a shared nothing architecture, does not support queries that require internode communication.GoalWe propose a new parallel processing architecture that integrates the relational DBMS with the DFS as a single system for big data analytics. The new architecture is novel in that the DBMSs directly access the entire DFS without having to partition and re-load the data. We present a prototype system, PARADISE, based on this architecture. With this integration, PARADISE effectively overcomes the drawbacks of HadoopDB.Features and Characteristics
 |
| Please send any suggestion or
comments for this page to webmaster@dblab.kaist.ac.kr
Last updated Mar. 14th, 2013 |
 |